Rethinking Imitation-based Planners for Autonomous Driving
[Arxiv Report] [Github] [BibTeX]
Abstract
In recent years, imitation-based driving planners have reported considerable success. However, due to the absence of a standardized benchmark, the effectiveness of various designs remains unclear. The newly released nuPlan addresses this issue by offering a large-scale real-world dataset and a standardized closed-loop benchmark for equitable comparisons. Utilizing this platform, we conduct a comprehensive study on two fundamental yet underexplored aspects of imitation-based planners: the essential features for ego planning and the effective data augmentation techniques to reduce compounding errors. Furthermore, we highlight an imitation gap that has been overlooked by current learning systems. Finally, integrating our findings, we propose a strong baseline model—PlanTF. Our results demonstrate that a well-designed, purely imitation-based planner can achieve highly competitive performance compared to state-of-the-art methods involving hand-crafted rules and exhibit superior generalization capabilities in long-tail cases. Our model and benchmarks are publicly available.
Benchmarks
For evaluation, 14 scenario types specified by the nuPlan Planning Challenge are considered, each comprising 20 scenarios. We examine two different scenario selection schemes:
(1) Test14-random: scenarios are randomly sampled from each type and fixed after selection.
(2) Test14-hard: in order to investigate the planner's performance on long-tail scenarios, we execute 100 scenarios of each type using a state-of-the-art rule-based planner (PDM-Closed), subsequently selecting the 20 least-performing scenarios of each type.
Metrics
We employ the official evaluation metrics provided by nuPlan. Detailed calculation methods can be found in nuPlan metrics.
(1) OLS: open-loop score.
(2) NR-CLS: closed-loop score with non-reactive traffic agents.
(2) R-CLS: closed-loop score with reactive traffic agents.
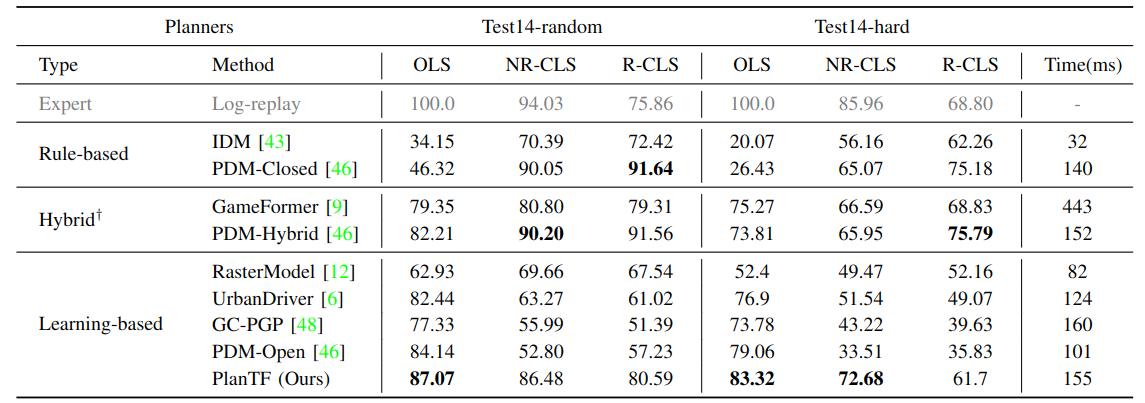
Main results
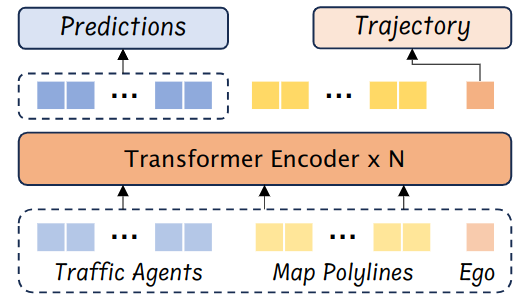
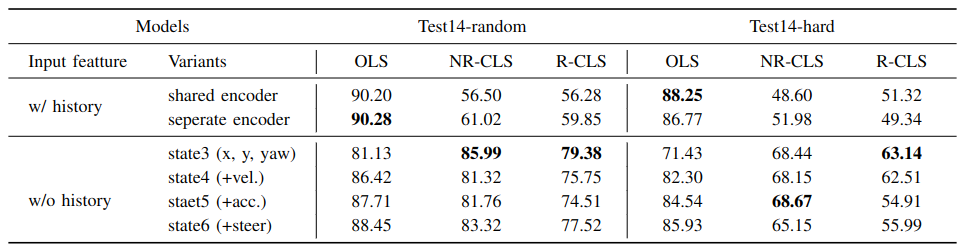
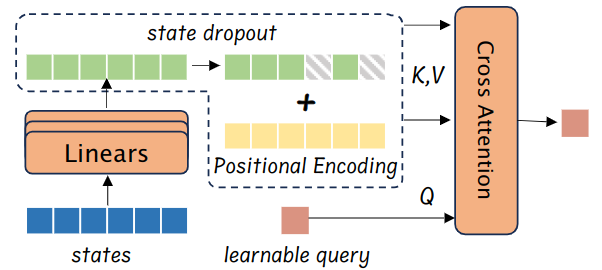
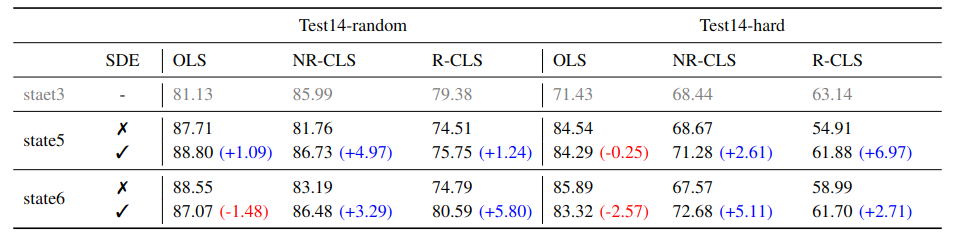
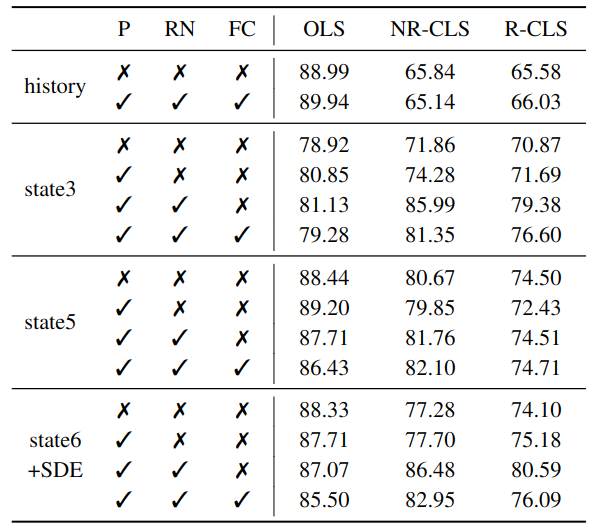
Comparison to state-of-the-art
Test14-hard example scenarios (Expert+LQR)
Click to play the videos (playspeed × 2.0).
Comparative results (Test14-hard, non-reactive)
We show the comparative results of our model and other state-of-the-art planners on the Test14-hard benchmark. The following examples scenarios demonstrate that while partially rule-based planner performs well on most of the ordinary scenarios, they may struggle to generalize to unusual/long-tail cases.
[1] D. Dauner et al., “Parting with misconceptions about learning-based vehicle motion planning", CoRL 2023.sharp right turn + change lane
sudden stop with leading vehicle
unprotected left turn
Consecutive lane change at pickup/dropoff
waiting for pedestrian at crosswalk (better viewed at fullscreen)
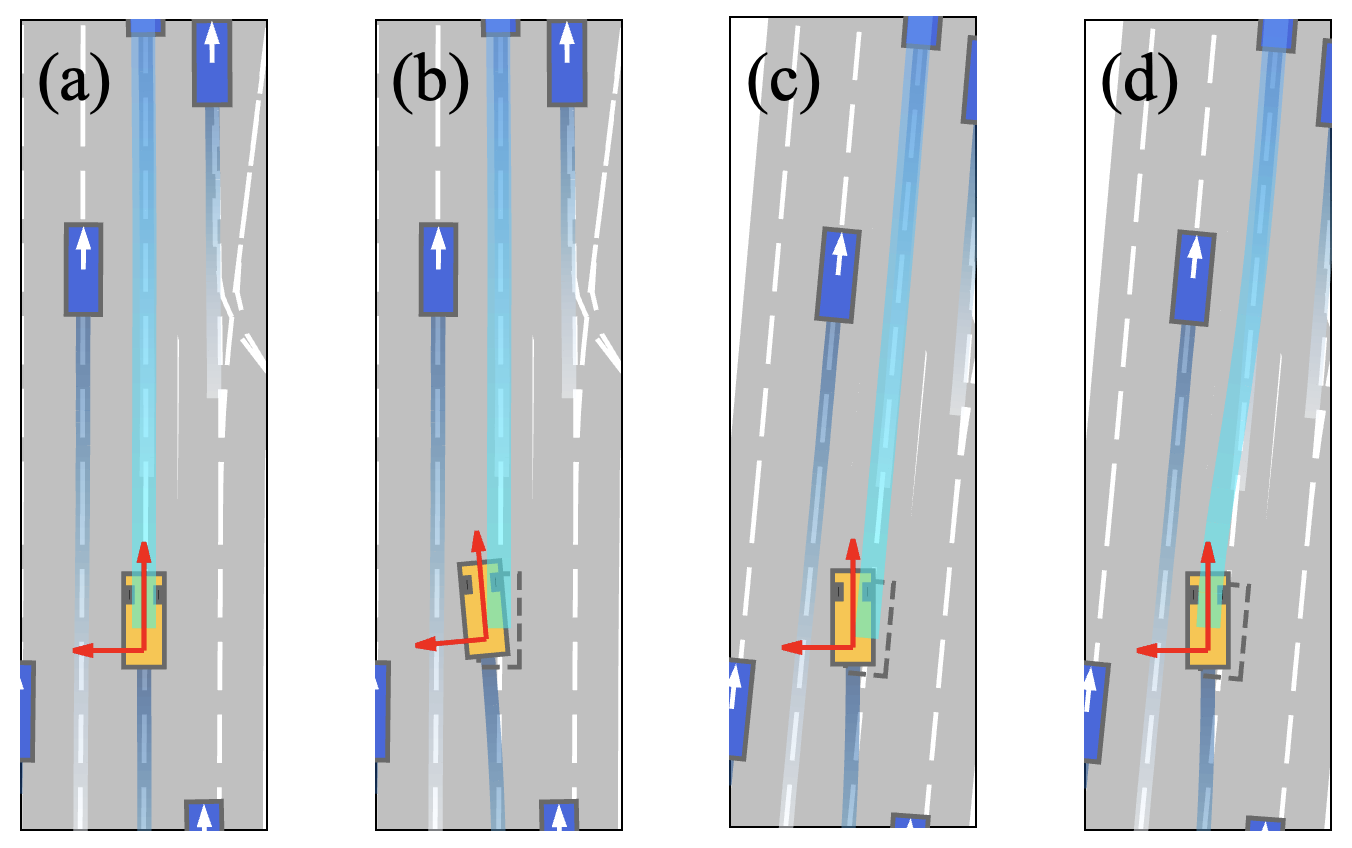
Limitation & Failure cases
Although our method significantly enhances pure imitation driving performance, it merely serves as a starting point and possesses substantial potential for improvement. We discovered that PlanTF often falters in scenarios necessitating dedicated operations and struggles to execute self-motivated lane changes. We attribute these issues primarily to the fundamental mismatch between open-loop training and closed-loop testing, reserving the exploration of closed-loop training for future work.
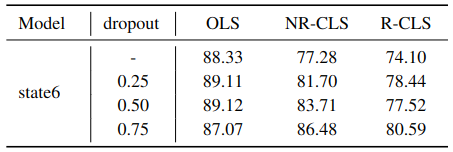
Appendix
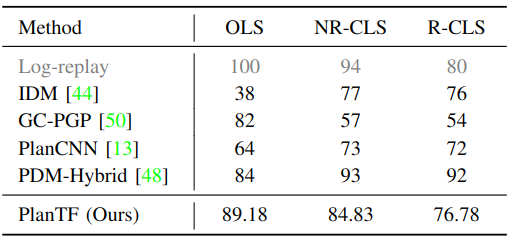
BibTeX
@misc{jcheng2023plantf,
title={Rethinking Imitation-based Planners for Autonomous Driving},
author={Jie Cheng and Yingbing Chen and Xiaodong Mei and Bowen Yang and Bo Li and Ming Liu},
year={2023},
eprint={2309.10443},
archivePrefix={arXiv},
primaryClass={cs.Ro}
}
Project page template is borrowed from DreamBooth.